Project ACG Search Engine
Note: Although langauge of content in this post is in English, some part of search results are in Chinese and Japanese.
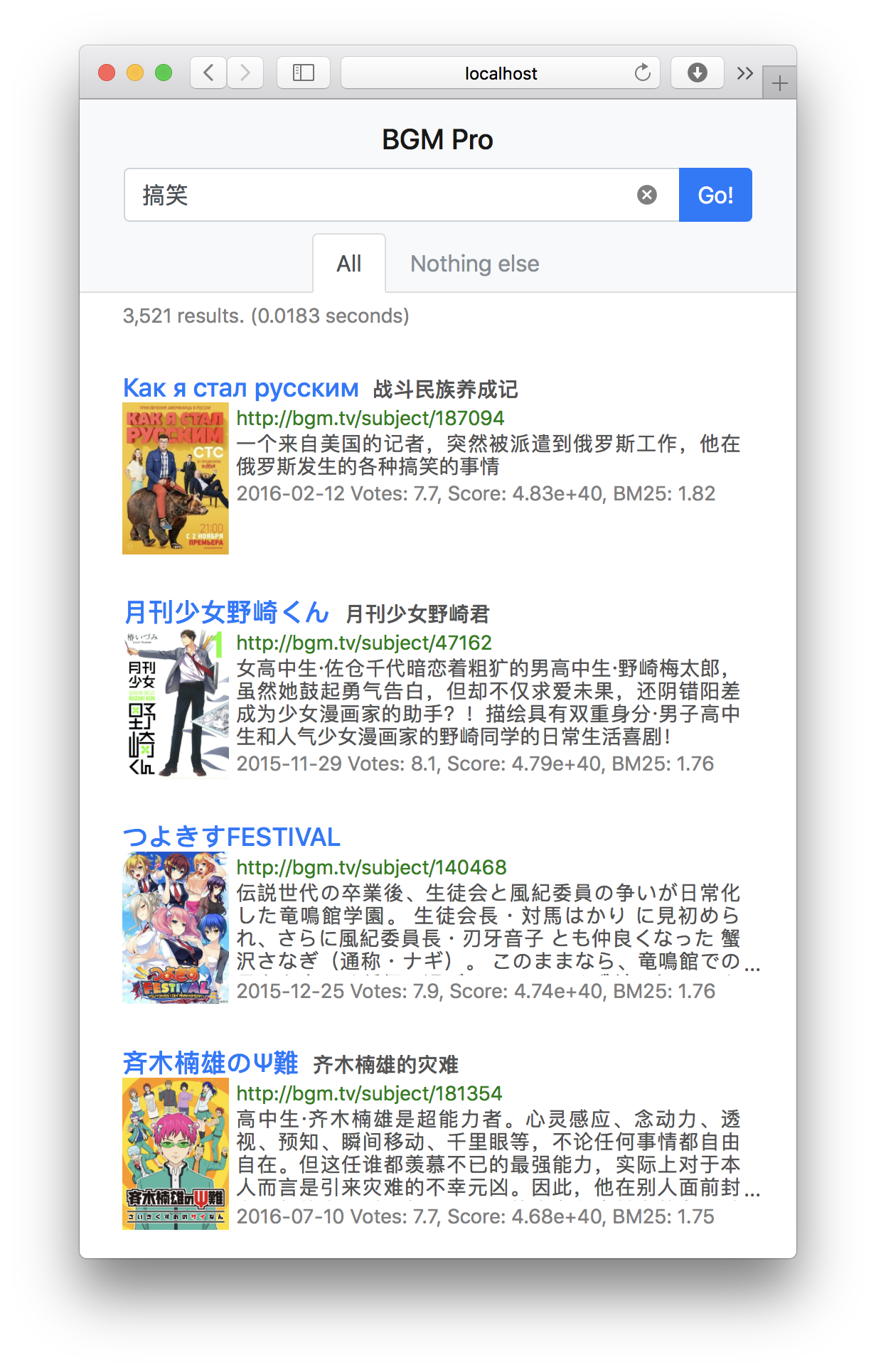
Bangumi Search is a specialized search engine for Anime, Comics and Games (ACG).
Intention
There is little search engine in market may search for ACG products for some given genre say “hilarious”. Although there are some search engine that may do similar job, they all come with some caveats. The following list several types of them:
-
Google.
Despite good at accrating good results, cannot give straight answers to the Problem.
Also they do not aggregate the result, that means if someone wants to find some products in minority (from an ambiguous query), it may not occur in all top 100 pages.
-
Netflix.
Despite the correct data scheme and refined search results, they don’t have much information on ACG datas.
-
AniDB.
A internet database for ACG products. Despite its good data source, it’s still a database, lacking of the ability to give good results.
Problem Definition
For a given query, give a list of related products in ACG, ordered in interestingness to that query. (Assuming user has already watched some of them, won’t be interested in those.)
Decomposition
The problem defined could be narrow down to a simpler question as the following:
- For a given genre or keyword, give a list of related products in ACG, ordered in interestingness to that query.
- Interestingness are relevance, goodness and freshness.
Data Source
Since watching using machine learning technology to find our interestingness is not realistic for the moment, the data source must contains high qualify user generated content (UGC) that helps search engine to understand “interestingness” for human.
In this project, data source is selected to be bgm.tv, a Chinese ACG fan website in Japanese and Chinese language.
Design
Overall, It’s divided into 3 main parts.

Crawling
Crawler is written on pyspider.
It first try to find the latest article added, then set the mission to crawl them all. Pyspider is configured to use mongoldb as mission database and redis to message Queue.
Building
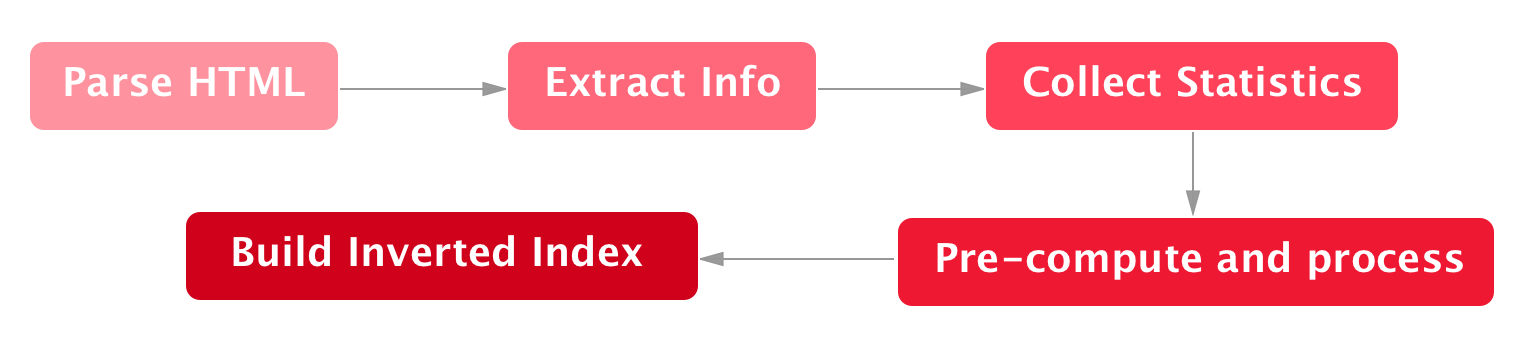
Querying
The ranking function is defined as:
\[\text{Score}(Q,d)=\text{BM25}(Q,d)\times \text{time}_{\text{norm}(now)}(d)^{\text{time-factor}}\times \text{rating}(d)^{\text{rating-factor}}\]where:
\[\text{BM25}(d, Q) =\sum_{t\in Q}IDF(t) \times \text{PartialBM25}(d,t) \times (k_1+1)\]where:
\[\text{PartialBM25}(d,t) = \frac{f_{d,t}}{K_d+f_{d,t}}\]where:
PartialBM25 is pre-calculated (in building stage.)
Results
Results are seems pretty good. I tested some queries and seemingly for the first 50 results, could not find any document that is “not relevant”.
The only problem is the ordering of them.
However by adjusting of parameters of ranking function, I couldn’t distinguish a result ordering whether they are good or not.
Thus I decided to let user decide their own parameter. (See factors in Design - Query)
Some thoughts
-
Click data won’t give much meaning since most people ignore those they’ve watch and only click what they are interested.
This doesn’t necessary mean the unclicked data are non-relevant.